Network Attacks
Attacks on protocols and applications hosted on the Network are plentiful. Web Applications are covered in its own section in this course.
Services can have inherent bugs in them allowing them to be exploited by attackers. These attacks typically involve using special instructions to the Operating System, via the vulnerable service, to take control of the process operating the network service. Buffer Overflows is a category of such attacks.
A network typically holds many applications, some which holds simple logins and others with complex functionality. One way to gain an overview of the attack surface, and also map out easy to exploit vulnerabilities, is to port scan all the assets in the target environment, then screenshot them.
Tools like EyeWitness (https://github.com/FortyNorthSecurity/EyeWitness) accomplish this. The tool allows us to quickly get an overview of which assets are represented on the network, then provides screenshots of each service. By having the screenshots we can easily look and assess quickly which systems we should take a closer look at.
Exploiting a service means to abuse the service in ways it was not intended to. Often this exploitation activity means the attackers are capable of running their own code, this is called RCE ("Remote Code Execution").
Buffer Overflow
Exploitation of network services sometimes involve abusing memory management functions of an application. Memory management? Yes, applications need to move around data within the computers memory in order to make the application work. When programming languages give the developer control of memory, problems like Buffer Overflow might exist. There exists many similar vulnerabilities, and in this section we review Buffer Overflows.
Programming language C and C++ allows developers very much control of how memory is managed. This is ideal for applications which requires developers to program very closely to the hardware, but opens up for vulnerabilities. Programming languages like Java, JavaScript, C#, Ruby, Python and others does not easily allow developers to make these mistakes, making Buffer Overflows less likely in applications written in these languages.
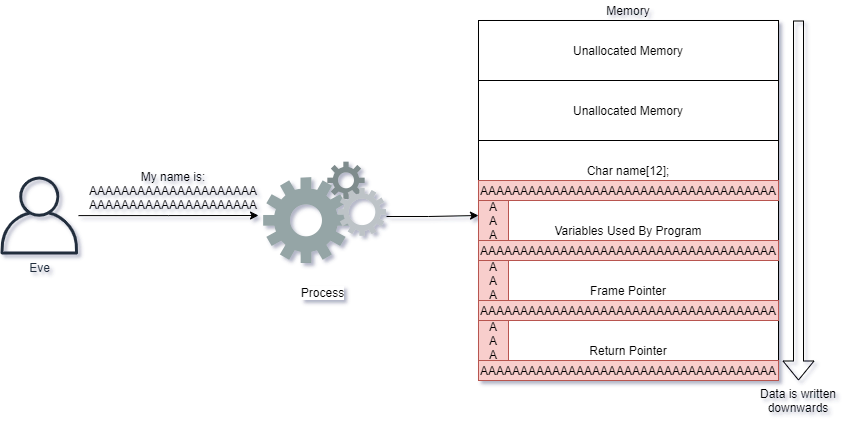
Buffer Overflows happen when un-sanitized input is placed into variables. These variables are represented on the Operating System via a memory structure called a Stack. The attacker can then overwrite a portion of the stack called the Return Pointer.
Note: The stack memory structure is simply where a program stores variables and information it needs to run. The stack will be located within a computers RAM ("Random Access Memory")
The Return Pointer decides where the CPU ("Central Processing Unit") should execute code next. The CPU simply controls which instructions the system should perform at any given moment. The return pointer is simply an address in memory where execution should happen. The CPU must always be told where to execute code, and this is what the return pointer allows it to do.
When attacker is able to control the Return Pointer, it means the attacker can control which instructions the CPU should execute!
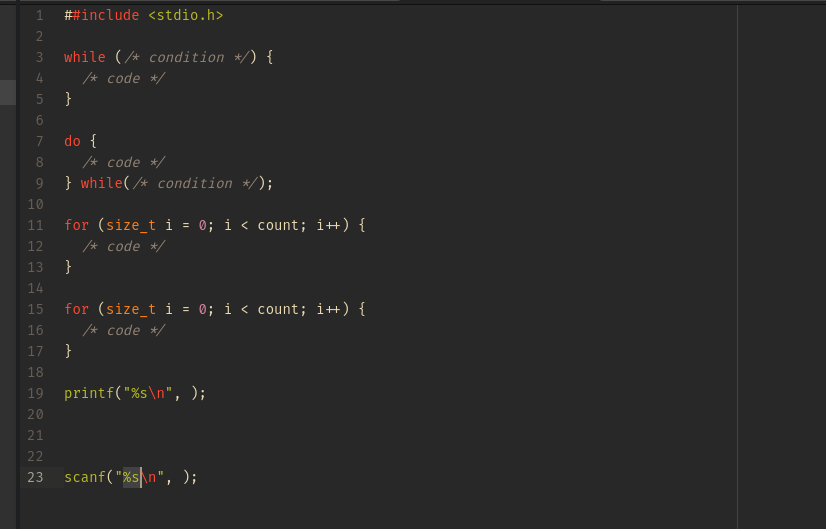
For example consider the following code C example (do not worry, you do not have to be a C developer, but do your best to try understand what this simple application does):
#include <string.h>
void storeName (char *input) {
char name[12];
strcpy(name, input);
}
int main (int argc, char **argv) {
storeName(argv[1]);
return 0;
}
In many programming languages, including C, the application starts within a function called main. This is indicated in the code above where it says int main (int argc, char **argv) {. Inside the curly brackets { and } the program simply runs a function called storeName(argv[1]);. This will simply accept whatever the user has typed into the program and provides it to the storeName function.
The application has 11 lines of code, but focus your attention on the line that reads strcpy(name, input);. This is a function which tries to copy text from input into the variable called name. Name can hold maximum 12 characters as indicated by the line saying char name[12];. Is there any place in the code that prevents the name supplied being longer than 12 characters? The name variable is supplied by the user whom is using the application and is passed directly into the storeName function.
In this application there is no cleaning or sanitization, making sure the length of the inputs are what the application expects. Anyone running the program can easily input a value larger than what the name variable can hold as a maximum. The name variable holds 12 characters, but what happens when the CPU is told to write more than 12 characters? It will simply perform what is has been told to, overwriting as much memory as it needs to!
When a larger than expected value is attempted written, the CPU will still attempt to write this value into memory. This effectively causes the CPU to overwrite other things in-memory, for example the Return Pointer allowing attackers to control the CPU. Again, if the attacker can overwrite and control the Return Pointer, the attacker controls which code the CPU should execute.
A graphical example shows Alice writing her name into the application we used in the example above:
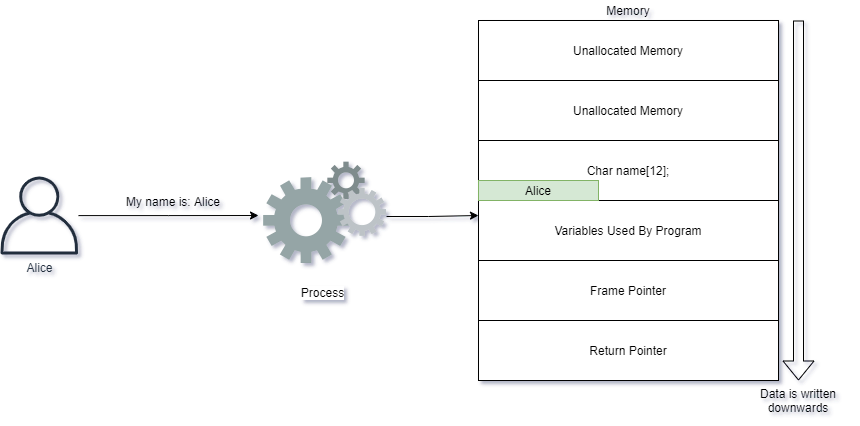
Alice behaves nicely and provides a name which causes the application to behave as it should. She provides her name Alice and it is simply written into the applications memory.
Eve however sends too many characters into the application. What happens then? The CPU effectively takes her input and writes the input into memory, also overwriting other values that exists!
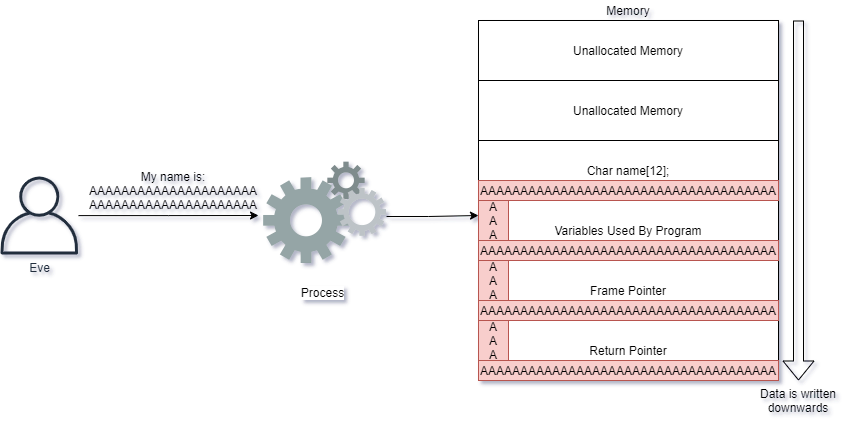
Eve's input caused the CPU to write much more data than what the application expected, and it caused the return pointer to be overwritten. When the CPU tries to execute the next instruction, it is now told to execute code at the location of AAAAAAA...
If Eve were to take control of this server, instead of writing A's, she would instead have to provide code that the CPU can understand into the memory. Next she would make the return pointer have a value which tells the CPU to execute Eve's own CPU code.
Note: Simply put, buffer overflows allows attackers to take control of a victims CPU by carefully overwriting the memory of the victim.
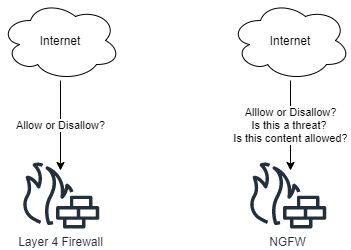
Vulnerability Scanners
A vulnerability scanner looks for common vulnerabilities in software and configurations across the network, automatically. It is not designed to find new classes of vulnerabilities, but instead uses a list of pre-defined plugins (or modules) to scan services for issues and vulnerabilities. It does not necessarily hunt for zero-day vulnerabilities! A zero-day vulnerability is a brand new vulnerability which is previously unknown to the vendor of the software and the defenders; for a zero-day vulnerability there currently exists no known patches for the problem.
The scanners have network mapping and port scanning features, including ways to explore and find vulnerabilities in the different applications it encounters.
A vulnerability scanner often supports configuration with credentials, allowing it to log onto systems and assess vulnerabilities instead of finding them from an unauthenticated perspective.
Note: Vulnerability scanners are mostly looking for known vulnerabilities and mis-configurations, not zero-day vulnerabilities!
Code Execution
When attackers have found a vulnerability which they are capable of exploiting, they need to decide on what payload they want to run. The payload is the code the attacker wants to have delivered through an exploit.
There are many different payloads an attacker can decide to use, here are some examples:
- Make the victim register with a C2 ("Command and Control") server accepting commands from attackers
- Create a new backdoor user account on the system so the attacker can use it later
- Open a GUI ("Graphical User Interface") with the victim so the attacker can remotely control it
- Receive a command line terminal, a shell, which attacker can send commands through
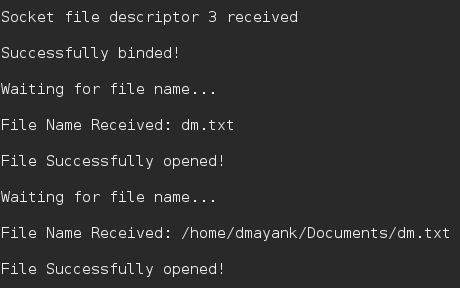
A payload common by attackers is a bind-shell. It causes the victim to listen on a port, and when the attacker connects they receive a shell.

Firewalls are helpful in preventing attackers from connecting to victims. A firewall would effectively deny incoming connections to the victim as long as the port is not allowed. Only one application can listen on a port, so attackers can not listen on ports that are already in use unless they disable that service.
To circumvent this defensive measure, attackers will instead try make the victim connect to the attacker, making the victim serve up access to the payload. Many firewalls unfortunately are not configured to deny egress traffic, making this attack very viable for attackers.
In this example we see an attacker using a reverse-shell to make the victim connect to the attacker.

Note: Code executions means attackers can run their code on the victims system. What code they choose to deploy is up to them, but it often involves attackers having a way to run commands on the victims system long term.
Network Monitoring
Attackers require the network in most cases to remotely control a target. When attackers are capable of remotely controlling a target, this is done via a Command and Control channel, often called C&C or C2.
There exists compromises via malware which is pre-programmed with payloads which does not need C2. This kind of malware is capable of compromising even air-gapped networks.
Detecting compromises can often be done via finding the C2 channel. C2 can take any form, for example:
- Using HTTPS to communicate to attacker servers. This makes the C2 look like network browsing
- Using Social Networks to post and read messages automatically
- Systems like Google Docs to add and edit commands to victims
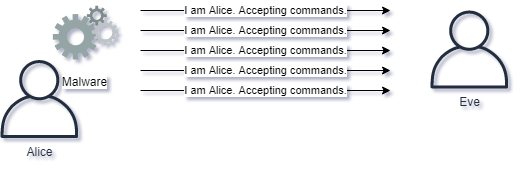
Only an attackers ingenuity sets the limit for C2. When considering how to stop attackers with clever C2 channels, we must often rely on detecting statistical anomalies and discrepancies on the network. For example network monitoring tools can detect:
- long connections used by C2, but which is unnatural for the protocol in question. HTTP is one of those protocols where it is not very common to have long connections, but an attacker using it for remote control might.
- Beacons used by C2 to indicate the victim is alive and ready for commands. Beacons are used by many kinds of software, not just attackers, but knowing which beacons exists and which you expect is good practice.
- Strobes of data suddenly bursting from the network. This might indicate a large upload from an application, or an attacker stealing data. Try understand which application and user is causing strobes of data happening and apply context to it. Is it normal or not?
There exists many ways defenders can try to find anomalies. These anomalies should be further correlated with data from the source system sending the data.
For network monitoring, context should be applied to help determine noise from signal. That means that a SOC ("Security Operations Center") should try to enrich data, for example Source and Destination IP Addresses with context to help make the data more valuable.
Applying context can be described with the following scenario: An attack arrives from the Internet but it tries to exploit a Linux vulnerability against a Windows service. This would typically be considered as noise and could safely be ignored; unless, what if the IP address doing the attack is an IP address from your own network or a provider whom you trust? The context which we can apply can then provide valuable insight into us exploring the attack further. After all, we don't want systems we trust launching any attacks!
Peer to peer traffic
Most networks are configured in a client to server fashion. Client access the servers for information, and when clients need to interact with one another they typically do it via a server.
An attacker however will likely want to use peer-to-peer, i.e. client to client, communications to leverage low hanging fruits like re-using credentials or exploiting weak or vulnerable clients.
For example port 445, used by SMB, is a good indicator to use for detecting compromise. Clients should not be talking to one another via SMB in most environments, however during a compromise it is likely an attacker will try use SMB to further compromise systems.

Lateral Movement and Pivoting
Once a system is compromised, an attacker can leverage that system to explore additional networks the compromised system has access to. This would be possible in an environment where a compromised system has more privileges through the firewall, or the system has access to other networks through e.g. an additional network card.
Pivoting means an attacker uses a compromised host to reach into other networks. An illustration of this is shown here where Eve has compromised one system and is using it to scan and discover others:

-768.png)
Web applications are everywhere today, and they are used to control just about everything you can imagine. In this section we will look into web application attacks and security.
IDOR ("Insecure Direct Object Reference")
IDOR vulnerabilities happen when developers have not implemented authorization requirements to access resources.

Eve, by simply changing an identifier, e.g. the document Rest parameter, she can access Alice's documents.
This happens when the web application does not enforce authorization between objects, allowing attackers to enumerate values and test access to other points of data.
For example we might have the following pseudo-code showing no signs of authorization:
$id = getInputFromUser();
$doc = getDocument($id);
return $doc;
The code above asks for input from user, performs no validation or sanitization, then performs a lookup with the getDocument function directly and returns the document in question.
A better implementation would be to check the privileges:
$id = getInputFromUser();
$user = findUsername();
$doc = "";
if (hasAccessToDocument($user, $id)) {
$doc = getDocument($id);
} else {
$doc = "Not authorized for this document";
}
return $doc;
Vulnerabilities like these are easy to find as you can simply change a simple number and see if you get access to someone else's data. Checking if the user is authorized first prevents this vulnerability.
Note: Pseudo code simply means code which resembles real code, but might not actually work. It is used to make an example of actual code.
Avoiding "Magic Numbers"
An application want to avoid using sequences of numbers when referencing data. In the IDOR example, the documents had identifiers from 1000 to 1002. Sometimes these numbers are called "Magic Numbers" as they directly point to a resource on the server, e.g. via database, and all values can easily be enumerated. For example an attacker can check all document identifiers from 0 all the way to 10000 and record any results which provides access to data.
While authorization should be properly implemented, it is also helpful to use GUID ("Globally Unique Identifier") or UUID ("Universally Unique Identifier") when referencing data. These identifiers are designed to be globally unique and impossible to enumerate because of the built-in entropy of the generation of the numbers.
This is what a GUID can look like:
- 3377d5a6-236e-4d68-be9c-e91b22afd216
Note: If you were to look at the mathematics behind guessing the number above, we would quickly see it is not easy to enumerate. Enumeration is a technique which can be used to walk through all possible options of a value, the GUID or UUID prevents this.
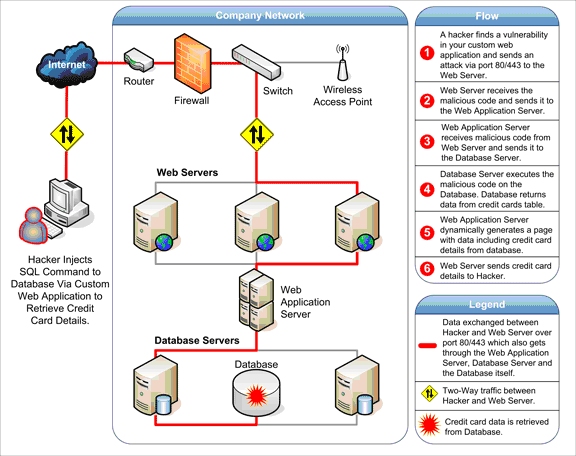
SQL Injection
Many web applications are connected to a database. The database holds all the information the web application wish to store and use.
SQL Injection is a technique which allows attackers to manipulate the SQL ("Structured Query Language") the developer of the web application is using. This typically happens because of lack of data sanitization. SQL is used regularly by developers to access database resources.

In the request Eve makes in the graphic above, we see she inputs the value: 1000' OR '1'='1
This causes the resulting SQL Query to return all rows of the table because the database evaluates the statement as always true. Think about it: the database receives a request where the value can be either 1000 OR 1 is equal to 1; it will return a value every time! There are many different SQL functions and operations we can use to manipulate the syntax, and this example is just one of very many.
Below is a pseudo-code example which contains a SQL Injection vulnerability.
$username = getUserName();
$pw = getPassword();
$user = mysql_query("SELECT * FROM userTable WHERE username = $username AND password = $pw");
if ($user) {
$loggedIn = True;
} else {
$loggedIn = False;
}
We can see there is no sanitization on both the username and password variables; instead they are used directly in the SQL causing the vulnerability to occur. The code allows the $loggedIn variable to be set if the query returns anything.
For an attacker to exploit this, they could simply craft a URL against the target domain with the attack in it like this:
/login?username=admin&password=password' OR '1'='1
The password variable is set to contain the SQL characters, causing the resulting SQL string to return a row, even if the password is unknown to us. The resulting SQL query would be:
SELECT * FROM userTable WHERE username = 'admin' AND password = 'password' OR '1'='1'
Parameterized queries is the recommended solution to defeat SQL Injections. Within a parameterized query, the developers carefully ensure each input to the query is defined as a specific value and type. Here is an example from the above code which is considered a secure implementation:
$username = getUserName();
$pw = getPassword();
$parameterizedQuery = prepare_query("SELECT * FROM userTable where username = ? and password = ?");
$parameterizedQuery.setString(1, $username)
$parameterizedQuery.setString(2, $password)
$user = parameterizedQuery.execute();
if ($user) {
$loggedIn = True;
} else {
$loggedIn = False;
}
In the above example, the developer has carefully said that parameter 1 should be a string and contain the username, and the password in the second parameter.
Note: SQL Injection is made possible because developers are not carefully sanitizing the input from users, and thus allows an attacker to fool the application and database into running unauthorized SQL code.
XSS ("Cross-Site Scripting")
XSS uses the server to attack visitors of the server. The attack does not target the server itself, but instead the users.
The server is simply used to reflect attackers values, typically JavaScript, against visitors who then run the attackers data in their own browser. The attacker has to craft an input which the server does not clean and sanitize, that way when a visitor clicks a link containing the attackers values, or visits a resource on the webpage which the attacker has used in their attack, the user runs code which the attacker supplied.
Here is a graphical example of Eve sending a link to Alice which contains the XSS attack:

This attack is called a Reflected XSS and involves Eve finding the vulnerability, then sending a link containing the attack to an unsuspecting user and having them click the link. The link contains the attack and makes the webserver return the attack to the victim clicking the link.
The code behind this could be something simple as this pseudo-code example:
$nickname = etNickName();
echo "Greeting $nickname, nice to meet you!";
Another kind of XSS is called a Stored XSS attack. In Stored XSS attacks the attacker is capable of saving content on the webpage which is reflected every time someone visits the website. It does not require someone to click a link necessarily.
This graphic describes how Eve is able to store malicious JavaScript to be executed in anyone's browser when the visit the resource:

XSS attacks can accomplish many things, for example:
- Stealing cookies which can be used for authentication
- Defacing the website, presenting content which the webserver did not intend to
- Phishing users in leaving credentials in fake login forms
To defend against XSS there are several best-practices to follow:
- Let the webserver return CSP ("Content Security Policy") headers which strictly decides where and how JavaScript is executed from
- Safely encode the output the webserver returns to users, effectively turning HTML characters into encoded safe characters
HTML Encoding
HTML encoding allows the web application to return typically unsafe characters in a safe manner. For example the following special characters can be encoded into their respective counterpart:
|
Special Character
|
HTML Entity
|
|
<
|
<
|
|
>
|
>
|
|
"
|
"
|
|
&
|
&
|
|
'
|
'
|
A potent and important area to computer security is WIFI. Devices and systems are no longer required to be interconnected via physical cables, but can instead be reached by anyone within signal radius. WIFI enables many new devices to be capable of networking.
WIFI Basics
WIFI as most people know it stems from the IEEE 802.11 protocol. There are other protocols which uses radio for signaling too, for example:
- Bluetooth, for communicating with devices we carry, typically smartphones, headphones etc.
- NFC ("Near Field Communications"), implemented in access badges and credit cards for wireless transmission of data.
- RFID ("Radio Frequency Identification"), used for access cards and other devices, for example a car which can wirelessly transmit its identifier to a toll-road system.
- ZigBee and Z-Wave, used for enterprise and home automation.
Wireless communication is typically done via an AP ("Access Point"), a wireless base station which acts as a switch and router between clients that wish to communicate. Peer-to-peer communications are also possible, but less typical.
The name of a wireless network is known as the SSID ("Service Set Identifier").
Because WIFI signals reach everyone in the vicinity it enables attackers to easily use an antenna to "sniff" communications for anyone transmitting. Sniffing simply means to listen for packets which the network interface can see.
WIFI sometimes allow users to reach internal applications, increasing attack potential. Furthermore, WIFI devices have management interfaces and firmware which can hold vulnerabilities, sometimes not always patched as timely as other assets in the enterprise.
WIFI Security
WIFI have the option of
- No security
- Access list based on MAC addresses
- PSK ("Pre-Shared Key")
- Enterprise authentication
Many WIFI attacks rely on network cards with two primary features, namely:
- Monitor Mode: Makes the network card forward packets destined to all MAC addresses to the Operating System, not just its own.
- Packet Injection: The network card supports crafting packets with a different source MAC address than its own.
Open WIFI Networks
An open WIFI network is a network with no password on it. Communication between AP and Clients is not encrypted and everyone has to rely on their own sources of encryption to protect their traffic. These kinds of networks are very convenient and accessible for users, but makes security compromises.
An attacker on these kinds of networks can easily see what everyone else is doing by simply sniffing packets. Such packets can contain sensitive details or simply details about what the users are doing on the network.

Hidden SSID
AP's can often turn off broadcasting the name of the wireless network. This requires clients to demonstrate knowledge of the SSID to join the network. It is not considered best-practice to enable hidden SSID, because the name of the network is exposed anytime a client joins. Furthermore, the clients now need to ask and broadcast information about the network they want to join, everywhere they travel. An attacker could then sniff the WIFI traffic of clients and potentially learn more information about whom the clients are and where they have joined networks before.

MAC Address Filtering
Some AP's support access control based on MAC Addresses. The AP can create an allow-list of which MAC addresses should be allowed to join and communicate on the network.
This approach is in-secure. An attacker can sniff and observe other systems communicating on the network already. Then record their MAC addresses and update the attackers own MAC address to be one which is already allowed. This effectively bypasses the MAC Address Filtering requirement.
PSK ("Pre-Shared Key")
PSK simply means the network is configured with a password. PSK protection is typically implemented via a protocol called WPA ("WIFI Protected Access"). Older protocols for authentication can also be used, for example WEP ("Wired Equivalent Privacy") but has for a long time been considered obsolete as it is highly in-secure and easy for attackers to crack.
WPA comes in different forms with WPA3 being the latest standard as of the year 2021. WPA is not entirely safe against attackers either, but offers much more protection than WEP. To break into a WPA enabled network the attacker must try to crack the password with a password cracker. This is considered an expensive process in terms of time if the password is reasonably strong.
If an attacker can observe (sniff) anyone whom authenticates to the network, they have enough to engage in password cracking activities. Tools like aircrack-ng ("https://www.aircrack-ng.org/") supports cracking WIFI passwords.
Enterprise Authentication
Enterprise Access Points can also support authenticating clients based on certificates, which requires PKI ("Public Key Infrastructure") or enterprise credentials by integrating to a centralized authentication service.
This has some benefits, especially the concept of key management. With a PSK network, the inherent challenge is how passwords are distributed, rotated and revoked.
While Enterprise Authentication provides better security management regarding keys, it also involves a more complex infrastructure and offers other opportunities for attackers.
Fake WIFI Access Points
Attackers can easily start broadcasting networks pretending to be other networks. Often clients will automatically connect to networks in range if they present themselves with the appropriate SSID. This allows attackers to make clients connect to the attackers network, allowing them to sniff and change traffic as the attacker wishes.

Penetration Testing & Social Engineering
Penetration testing serves as a pro-active measure to try identify vulnerabilities in services and organizations before other attackers can.
Penetration testing can be offered within many areas, for example:
- Web applications. There are new web-applications developed and released.
- Network and Infrastructure. Many applications are not a web-application, but instead uses other protocols. These organization applications can reside both externally and internally.
- Inside testing / Infected computer simulation. What if a user receives malware on their system? This would be nearly equal to an attacker having hands-on-keyboard on that system, posing a serious risk to any organization.
- External Organizational Testing. A test which holds within the entire organization as scope for the penetration testers. This is ideal, but often involves having their own internal penetration testing team to focus on this long-term, or high costs involving hiring an external team to do this test.
- Stolen Laptop Scenario. Further described in our scenarios below.
- Client Side Applications. Many applications exists in an enterprise written in different languages such as C, C++, Java, Flash, Silverlight or other compiled software. A penetration test could focus on these assets too.
- Wireless networks. A test which serves to figure out if the WIFI can be broken into, if devices have outdated and vulnerable software, and if proper segmentation has been built between the wireless network and other networks.
- Mobile applications (Android, Windows Phone, IOS). Mobile applications can have vulnerabilities in them, and also include connections and references to systems hosted inside the enterprise. Mobile applications can also hold secrets such as API keys which can easily be taken advantage of by attackers.
- Social Engineering. Further described in our scenarios below.
- Phishing and Vishing. Further described in our scenarios below.
- Physical. A penetration testing team could try to see what happens if they show up at a location with a laptop and plugs into a network connection. Physical attacks can also include other kinds of covert attacks against locations.
- ICS ("Industrial Control Systems") / SCADA ("Supervisory Control And Data Acquisition"). These systems typically controls some of the most vulnerable and critical assets in organizations, and as such they should receive scrutiny.
No-knowledge, Partial-knowledge and Full-Knowledge Penetration testing
Depending on the engagement, the organization can decide to give information to the team doing the penetration testing. A no-knowledge penetration, sometimes called a black-box, implies the attacker is given no-knowledge in advance. Partial-knowledge, sometimes called a grey-box test, means the attackers are given some knowledge, and with a full-knowledge penetration test, sometimes called white-box, the penetration testers have everything they need from source-code, network-diagrams, logs and more.
The more information an organization can give the penetration testing team, the higher value the team can provide.
Stolen Laptop Scenario
A great penetration test scenario is to prove the consequences of a stolen or lost laptop. Systems have privileges and credentials on them that attackers could use to get into the target organization.
The system might be protected with a password, but there exists many techniques which may allow the attackers to bypass this protection. For example:
- The systems hard-drive might not be fully encrypted, allowing an attacker to mount the hard-drive on their own system to extract data and credentials. These credentials could in turn be cracked and re-used across many of the organizations login pages.
- The user might have locked the system, but a user is still logged in. This user has applications and processes running in the background, even if it is locked. The attackers could try to add a malicious network card to the system via for example USB. This network card tries to become the preferred way for the system to reach the internet. If the system uses this network card, the attackers can now see the network traffic and attempt to find sensitive data, even change data.
As soon as the attackers have access to the system they can start to raid it for information, which can be used to further drive the attackers objectives.
Social Engineering
A system is only as strong as the weakest member, and that is often a human being. Social Engineering involves targeting users with attacks trying to fool them into doing actions they did not intend to. This kind of technique is very popular and many of the biggest hacks in the world has involved using social engineering techniques.
Social Engineering often tries to abuse certain aspects to make victims comply with actions, for example:
- Most people have the desire to be polite, especially to strangers
- Professionals want to appear well-informed and intelligent
- If you are praised, you will often talk more and divulge more
- Most people would not lie for the sake of lying
- Most people respond kindly to people who appear concerned about them
When someone has been victimized with a good social engineering attack, they often do not realize they have been attacked at all.
Social Engineering Scenario: Being Helpful
Humans usually wants to be helpful to each other. We like doing nice things!
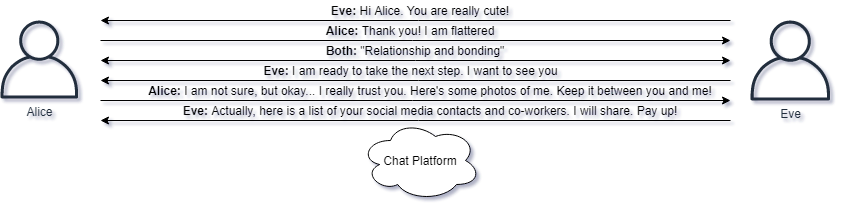
Consider a scenario where Eve runs into the reception of a big corporate office with her papers soaked in coffee. The receptionist can clearly see Eve in distress and wonders what is going on. Eve explains that she has a job interview in 5 minutes and she really needs her documents printed out for the interview.
In advance Eve has prepared a malicious USB stick with documents designed to compromise computers it is plugged into. She hands the receptionist the malicious USB stick and, with a smile, asks if the receptionist can print the documents for her. This might be what it takes for attackers to infect a system on the internal network, allowing them to compromise(pivot) more systems.
Social Engineering Scenario: Using fear
People often fear of failing or not do as ordered. Attackers will often use fear to try coerce victims into doing what the attackers need. They can for example try to pretend to be the company director asking for information. Perhaps a social media update revealed the director is away on vacation and this can be used to stage the attack.
The victim probably does not want to challenge the director, and because the director is on vacation, it might be harder to verify the information.
Social Engineering Scenario: Playing on Reciprocation
Reciprocation is doing something in return, like a response to someone showing you kindness.
If we consider someone holding the door for you to let you in the front-door of your office building. Because of this, you are likely to want to hold the next door for the person to reciprocate. This door might be behind access-control, needing employees to present their badges, but to offer the same kindness in return, the door is held open. This is called tailgating.
Social Engineering Scenario: Exploiting Curiosity
Humans are curious by nature. What would you do if you found a USB stick lying on the ground out-side the office building? Plug it in? What if the USB stick contained a document with the title "Salary Information - Current Updates"?
An attacker could deliberately drop many malicious USB sticks around the area where employees reside, hoping someone will plug them in.
Documents can contain malicious macros or exploits, or simply trick users into performing certain actions which makes them compromise themselves.
Phishing
Phishing is a technique usually done through email. Attackers will try to coerce and trick employees into giving away sensitive details such as their credentials or have them install malicious applications giving attackers control of the system.

Phishing is a common technique for attackers to break in, something penetration testers also might try to exploit. It is important to never underestimate the human factor in cyber security. As long as humans involved, phishing will always be a possible way for attackers to gain access to systems.
Phishing should not be used to prove that humans make mistakes, but try prove the consequences of those mistakes. It can also be used to test the strength of anti-spam filters and user awareness.
A campaign of many phishing attempts can be done instead of a single round. A campaign of multiple phishing rounds can help determine the overall awareness of the organization and also let them know that not only attackers are trying to trick our users, but even the security department.
Vishing
Vishing means to use phone calls to try get unsuspecting employees to perform actions for the attackers. If the employee believes they are in a phone call with someone they know, preferably someone with authority, the employee can be tricked to performed unwanted actions.

Here is an example where Eve calls Alice:
Eve: Hello, this is Miss Eve calling. I was told to call you personally by the CEO Margarethe; she said you would be able to help.
Alice: Ok... What can I do for you?
Eve: Margarethe is travelling right now, but urgently requests her password to be reset so we can get on with a business meeting happening the moment she lands.
Eve: We urgently request for her email password to be reset so she can deliver the meeting.
Eve: Can you proceed to reset her password to Margareth123?
Alice: I am not sure...
Eve: Please, Margarethe asked for you personally to comply with this request. It must be done now, I don't want to think of the consequences if not...
Alice: Ok. Password is reset
Vishing could try get victims to do information disclosure revealing sensitive information. It could be an attacker asking for a copy of a sensitive document or a spreadsheet.
.png)
Many systems are protected by a simple password. This is not ideal as passwords can in many cases easily be broken, reused, or otherwise abused by attackers. This section will explore attacks and defenses regarding passwords.
Password Strength
What determines a strong password? Is it how complex the password is? How many characters it has? The number of special characters?
The famous comic creator xkcd.com brilliantly shows how passwords can be attacked in the comic below. Review it for a second and let us discuss further.
Note: Entropy means the lack of predictability. The higher entropy, the harder to crack via standard means.
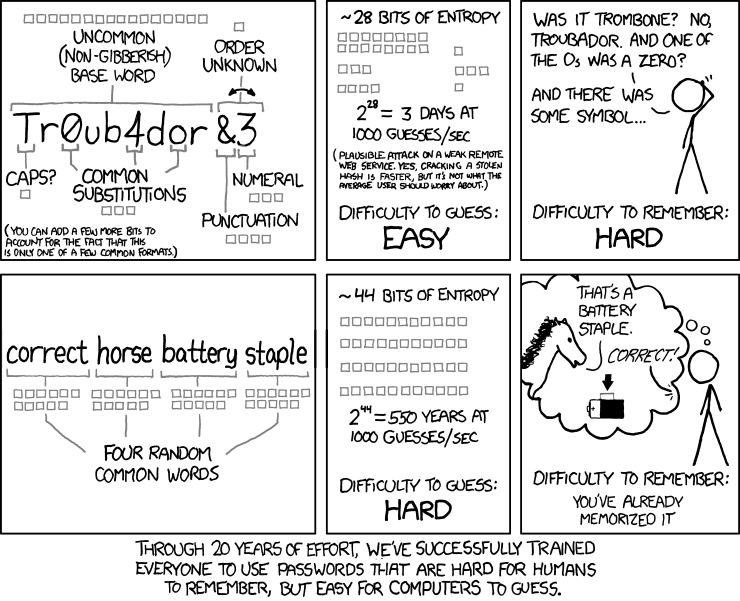
Comic from XKCD: https://xkcd.com/936/
If we consider the first password Tr0ub4dor&3, this password is will fit most password policy rules, for example having capitalized letter, numbers, special characters and a length of 11 characters. This password has however some problems, it is:
- Hard to remember. Did you replace the first o (the letter) character with a 0 (the number), or was it the second? Did you replace the a character with a 4, or not?
- Hard to type. You have to type in different letters, numbers and special characters in a special order. It will likely not be the fastest words being typed on your keyboard.
- It is not very strong! The password is based off a rather common word and it does not offer much strength, only about 28 bits of entropy.
Instead of selecting passwords which have these negative factors, we can instead greatly increase the entropy of passwords in simple ways. If we consider the password CorrectHorseBatteryStaple we see a considerate improvement of the password:
- The password is easy to type. Typing in regular words is for many an everyday activity and you can get really fast at it.
- It is easy to remember. By using a visual picture of the password, a horse, a battery, a staple and the word correct, we can remember it much easier.
- It is significantly stronger against most password cracking activities! It offers about 44 bits of entropy, making it really hard to crack.
Passwords like this one is called passphrases and is generally a much better practice than a simple word with some complexity. Consider how you could improve the password to be even stronger, and to fit password policy rules such as special characters and capital letters! You can even use spaces in your password, making passphrases even more natural to type.
Password Managers
Writing down your password has for many years been considered a bad-practice, but is it really? Using the same password across multiple services online has a significant risk, what if one of those platforms get hacked? Then that password is compromised and attackers can re-use the password across all other services where it is used.
To fight this problem, the recommendation is to not re-use the same password across multiple services. This makes it really hard for users as they are not only required to use unique passwords, but at the same time create strong and robust passwords! A password manager help solve this problem by offering users to, in a secure as possible way, write down passwords in a file, database or other system, making passwords easy accessible and ensuring they are strong and unique across different services.
When implemented correctly, a password manager will:
- Make the use of the Internet a much more secure activity
- Increase productivity as passwords for different services can easily be found, copied and pasted into the respective services the user want to log into
- Offer easy ways to reset and regenerate new passwords when needed.
Writing down passwords is considered a much lower risk for our users rather than having them reusing passwords. Yes, this is not a perfect solution as the password manager could potentially get compromised, however it is considered a much more safe approach.
Passwordless Solutions
What if passwords in themselves could be put to an end? There is always someone who can not type in a longer passphrase as their password every day. There may be several reasons for this, for example:
- Non IT savvy workers in the office
- A doctor who visits many different computers in the hospital, every day while visiting different patients in different rooms
- It is hard to type in the password on the system which requires it
The development and implementation of systems which does not require users to provide a password is developing rapidly. Instead of asking users to authenticate with a password, what if we allowed them to use for example:
- Something they are, for example their face or fingerprint
- Something they have, for example a token or their cell-phone
There are challenges to this, but in terms of security, are we really making the problem worse, or better for our users? We must remember we are not looking to implement perfect security systems, they are normally outside of reach and not implementable, so instead we must make careful considerations on how we can limit the threats and at the same time make life easier for our users. Passwords are not perfect, and neither is passwordless solutions. Which one will you implement for your users?
Multi-Factor Authentication
As we learn that regardless of what solution is used to verify users, there will still be significant risks associated with their accounts, other solutions can be implemented to help reduce the risk.
Multi-Factor Authentication allows solutions to not only verify a user based on for example their password, but at the same time require the users to present a second factor to prove who they are.

There can be several different ways to ask for a second factor. Here are a few examples:
- Use an authentication application on a smart-phone to provide a secret code
- Receive a secret code via SMS ("Short Message Service") on a phone
- Use a hardware token to provide a secret code
- Present a fingerprint or face to identify the individual
All of the above requires not only a password to be known, but also asks for a second item (a factor) to be provided.
Solutions like these are sometimes considered very invasive to the users. To help solve this problem a concept of DAC ("Discretionary Access Control") can be applied. DAC allows the login solution to consider whether or not to challenge a user with a multi-factor code. For example a multi-factor might only be necessary when a user:
- Logs in from a new location
- Uses a different browser or software to access the application
- Tries to perform a sensitive action in the application, for example change password or perform a money transaction above a certain threshold
Password Guessing
When attackers encounter applications and services, there might be the opportunity to do Password Guessing. Password Guessing is an activity which involves attackers interacting with the application over the network, trying lists of different combinations of usernames and passwords.
Password Guessing gives the attacker an opportunity to find accounts with a weak username and password combination.

If the attacker is successful in finding a valid account to log in with, new opportunities is presented to the attacker. Consider what kind of functionality and data is now presented to the attacker. Here are some examples where and attacker successfully guesses someone's password:
- Attacker accesses an email account of an employee. Inside there are thousands of emails ranging years back in history. Within the emails there are passwords communicated, allowing attacker to log into more systems. Furthermore, hundreds of attachments are present, some which may contain very sensitive information.
- Attackers successfully guess the Admin accounts password for an HVAC ("Heating, Ventilation and Air Conditioning") system who's responsibility is to cool down the server room. The attackers are able to change the parameters of the HVAC and through careful modification causes the server-room to overheat.
- A VPN service is available on the Internet, allowing employees to reach internal resources. One of the employees has a weak password which is guessed by an attacker through days of repeated password guessing. The attacker accesses the VPN service and is now on the inside network of the organization. From here, the attacker installs ransomware within the organization.
- A web application is deployed on the Internet. It holds no obvious vulnerabilities from the outside, however attackers were able password guess into a regular users account on the system. Because the company hosting the web application trusts their users, the web security on the inside of the application was poor. From here, the attacker was able to use web exploits to compromise the server.
Many network services have built-in administrator accounts, some even with the default password unchanged since it was installed. For each service on the network, attackers can try to log in with default credentials. Furthermore, the attacker can try typical and weak passwords. Here are some examples of typical and weak passwords. Notice all of them end with an exclamation mark in order to defeat password policies:
| Password |
Comment |
| Summer2021! |
Many people, including helpdesks of companies, perform password resets and set the password to the season of the year and the year we are currently in. |
| W3schools123! |
The name of the company is often used as peoples passwords. The number 123 and ! at the end is selected by users to pass password policies and make it a bit more complex. |
| Rosalynn2006! |
Rosalynn, perhaps someone's child? Users often use something of personal affection as their passwords. Names of children and perhaps the year they were born is very popular. |
| Qwerty123456! |
A seemingly random password? This password is someone pressing keyboard keys in order, then using numbers to do the same thing. |
A tool which allows us to easily configure lists of usernames and passwords to try against a multitude of different services is THC-Hydra (https://github.com/vanhauser-thc/thc-hydra). It supports plenty of protocols to attack such as:
- RDP ("Remote Desktop Protocol")
- FTP ("File Transfer Protocol")
- SMB ("Server Message Block")
- Telnet
- SSH ("Secure Sockets Host")
To use THC-Hydra to target for example FTP, the following command can be used:
hydra -L common_usernames.txt -P common_passwords.txt ftp://localhost/
This command uses a list of common usernames and common passwords to try each of them against the FTP service at localhost or an IP address of your choice.
Credential Stuffing
A common attack for attackers to use is Credential Stuffing. This involves attackers downloading huge databases of credentials and testing applicable credentials against the network service. A leak of credentials happen when a third party service is hacked, database is stolen and then leaked on the Internet for anyone to download.
Unfortunately many users re-use the same password on different services, allowing Credential Stuffing attacks to become very efficient against organizations.
Note: Anyone, including you, can go about searching the Internet for leaked databases containing credentials and passwords. It is not very hard to hack when people do not change their passwords?!
Password Cracking
While Password Guessing is an online attack, Password Cracking is an offline attack. It involves attackers stealing password representations from a target first.
Passwords are typically represented as a password hash. A hash is way to store users passwords by sending them through a one-way function, making the password impossible to reverse unless password cracking is used.
If the attacker is capable of retrieving credentials from a system, these credentials are likely to be protected via encryption or hashing. Hashing is a one-way function designed to not be reversed into its original value.
Password cracking involves using computing power, that is the CPU ("Central Processing Unit") and GPU ("Graphical Processing Unit"), to try create password guesses which matches the protected credentials retrieved from the system.
Note: The GPU is typically much better in password cracking because it has hundreds of micro cores which are all capable of doing small tasks on their own. This allows a password cracker to become much faster as it can scale the cracking activities over many different cores.
Services Without Authentication
By exploring and discovering applications sometimes you can encounter applications which are not protected with authentication. These applications are useful for attackers to explore, for example taking advantage of a search field hunting for sensitive information.
Many applications on a network can freely be explored, sometimes providing attackers with the exact data they are looking for.
When performing network mapping and port scanning exercises, each discovered system and service should be explored.
Using Existing Credentials
Typically an attacker is already using credentials of users in the environment. For example if an attacker has compromised someone's computer system they can re-use the credentials already in-use by the system.
This provides attackers with many more opportunities. Consider all the applications which could now be abused. For example:
- Email
- SharePoint
- HR and Accounting
- VPN ("Virtual Private Networking")
Once an attacker has access to an application behind access control, vulnerabilities and data is often plentiful.
Credentials from a system can also be extracted via different means, typically involving having administrator access of the system. Mimikatz (https://github.com/gentilkiwi/mimikatz) is such a tool which tries to dump the credentials from the system.
Security Operations is often contained within a SOC ("Security Operations Center"). Terms are used interchangeably.
Typically the SOC's responsibility is to detect threats in the environment and stop them from developing into expensive problems.
SIEM ("Security Information Event Management")
Most systems produces logs often containing important security information.
An event is simply observations we can determine from logs and information from the network, for example:
- Users logging in
- Attacks observed in the network
- Transactions within applications
An incident is something negative we believe will impact our organization. It might be a definitive threat or the potential of such a threat happening. The SOC should do their best to determine which events can be concluded to actual incidents, which should be responded to.
The SIEM processes alerts based on logs from different sensors and monitors in the network, each which might produce alerts that are important for the SOC to respond to. The SIEM can also try to correlate multiple events to determine an alerts.
SIEM's typically allow events from the following areas to be analyzed:
- Network
- Host
- Applications
Events from the network is the most typical, but least valuable as they don't hold the entire context of what has happened. The network typically reveals who is communicating where, over which protocols, and when, but not the intricate details about what happened, to whom and why.
Host events give more information in regards to what actually happened and to whom. Challenges such as encryption is no longer blurred and more visibility is gained into what is taking place. Many SIEM's are enriched with great details about what happens on the hosts themselves, instead of only from the network.
Events from application is where the SOC typically can best understand what is going on. These events give information about the Triple A, AAA ("Authentication, Authorization and Account"), including detailed information about how the application is performing and what the users are doing.
For a SIEM to understand events from applications it typically requires work from the SOC Team to make the SIEM understand these events, as support is often not included "out-of-the-box". Many applications are proprietary to an organization and the SIEM does not already have an understanding of the data the applications forward.
SOC Staffing
How a SOC is staffed greatly varies based on the requirements and structure of an organization. In this section we take a quick look at typical roles involved in operating a SOC. An overview of potential roles:

As in most organized teams, a role is appointed to lead the department. The SOC Chief determines the strategy and tactics involved to counter threats against the organization.
The SOC Architect is responsible for ensuring the systems, platforms and overall architecture is capable of delivering what the team members require to perform their duties. A SOC Architect will help build correlation rules across multiple points of data and ensures incoming data conforms to the platform requirements.
Analyst Lead is responsible that processes, or playbooks, are developed and maintained to ensure analysts are capable to find the information necessary to conclude alerts and potential incidents.
Level 1 Analysts serve as the first responders to alerts. Their duty is, within their capabilities, to conclude alerts and forward any troubles to a higher level analyst.
Level 2 Analysts are distinguished by having more experience and technical knowledge. They should also ensure any troubles in resolving alerts are forwarded to the Analyst Lead to aid the continuous improvement of the SOC. The Level 2, together with the Analyst Lead, escalates incidents to the Incident Response Team.
The IRT ("Incident Response Team") is a natural extension to the SOC Team. The IRT team is deployed to remediate and solve the issues impacting the organization.
Penetration Testers ideally also support the defense. Penetration Testers have intricate knowledge of how attackers operate and can help in root cause analysis and understanding how break-ins occur. Merging attack and defense teams is often referred to as Purple Teaming and is considered a best-practice operation.
Escalation Chains
Some alerts require immediate actions. It is important for the SOC to have defined a process of whom to contact when different incidents occur. Incidents can occur across many different business units, the SOC should know who to contact, when and on which communication mediums.
Example of an escalation chain for incidents impacting one part of a organization:
- Create an Incident in the appointed Incident Tracking System, assigning it to correct department or person(s)
- If no direct action happens from department/person(s): send SMS and Email to primary contact
- If still no direct action: phone call primary contact
- If still no direct action: call secondary contact
Classification of Incidents
Incidents should be classified according to their:
- Category
- Criticality
- Sensitivity
Depending on the incidents classification and how it is attributed, the SOC might take different measures to solve the issue at hand.
The category of incident will determine how to respond. There exists many kinds of incident and it is important for the SOC to understand what each incident type means for the organization. Example incidents are listed below:
- Inside Hacking
- Malware on Client workstation
- Worm spreading across the network
- Distributed Denial of Service Attack
- Leaked Credentials
The criticality of an incident is determined based on how many systems is impacted, the potential impact of not stopping the incident, the systems involved and many other things. It is important for the SOC to be able to accurately determine the criticality so the incident can be closed accordingly. Criticality is what determines how fast an incident should be responded to.
Should the incident be responded to immediately or can the team wait until tomorrow?
Sensitivity determines who should be notified about the incident. Some incidents require extreme discretion.
SOAR ("Security Orchestration, Automation and Response")
To counter the advancements of threat actors, automation is key for a modern SOC to respond fast enough. To facilitate fast response to incidents, the SOC should have tools available to automatically orchestrate solutions to respond to threats in the environment.
The SOAR strategy means ensuring the SOC can use actionable data to help mitigate and stop threats which are developing more real-time than before. In traditional environments it takes attackers very short time from the time of compromise until they have spread to neighboring systems. Contrary to this it takes organizations typically a very long time to detect threats that have entered their environment. SOAR tries to help solve this.
SOAR includes concepts such as IAC "Infrastructure as Code" to help rebuild and remediate threats. SDN ("Software Defined Networking") to control accesses more fluently and easily, and much more.
What to monitor?
Events can be collected across many different devices, but how do we determine what to collect and monitor? We want the logs to have the highest quality. High fidelity logs that are relevant and identifying to quickly stop the threat actors in our networks. We also want to make it hard for attackers to circumvent the alerts we configure.
If we look at different ways to catch attackers, it becomes evident where we should focus. Here is a list of possible indicators we can use to detect attackers, and how hard it is considered for attackers to change.
|
Indicator
|
Difficulty to change
|
|
File checksums and hashes
|
Very Easy
|
|
IP Addresses
|
Easy
|
|
Domain Names
|
Simple
|
|
Network and Host Artifacts
|
Annoying
|
|
Tools
|
Challenging
|
|
Tactics, Techniques and Procedures
|
Hard
|
File checksums and hashes can be used to identify known pieces of malware or tools used by attackers. Changing these signatures are considered to be trivial for attackers as their code can be encoded and changed in multiple different ways, making the checksums and hashes change.
IP Addresses are also easy to change. Attackers can use IP addresses from other compromised hosts or simply use IP addresses within the jungle of different cloud and VPS ("Virtual Private Server") providers.
Domain Names can also be reconfigured quite easily by attackers. An attacker can configure a compromised system to use a DGA ("Domain Generation Algorithm") to continuously use a new DNS name as time passes. One week the compromised system uses one name, but the next week the name has changed automatically.
Network and Host Artifacts are more annoying to change, as this involves more changes for the attackers. Their utilities will have signatures, like a user-agent or the lack of thereof, that can be picked up by the SOC.
Tools become increasingly harder to change for attackers. Not the hashes of the tools, but how the tools behave and operate when attacking. Tools will be leaving traces in logs, loading libraries and other things which we can monitor to detect these anomalies.
If the defenders are capable of identifying Tactics, Techniques and Procedures threat actors use, it becomes even harder for attackers to get to their objectives. For example, if we know the threat actor likes to use Spear-Phishing and then Pivoting peer-to-peer via to other victim systems, defenders can use this to their advantage. Defenders can focus training to staff at risk for spear-phishing and start implementing barriers to deny peer-to-peer networking.
Cyber Security Incident Response
What is an Incident
An Incident can be classified as something adverse, a threat, to our computer systems or networks. It implies harm or someone attempting to harm the organization. Not all Incidents will be handled by an IRT ("Incident Response Team") as they do not necessarily have an impact, but those which do the IRT is summoned to help deal with the incident in a predictable and high quality manner.
The IRT should be closely aligned to the organizations business objectives and goals and always strive to ensure the best outcome of incidents. Typically this involves reducing monetary losses, prevent attackers from doing lateral movement and stopping them before they can reach their objectives.
IRT - Incident Response Team
An IRT is a dedicated team to tackle Cyber Security Incidents. The team may consist of Cyber Security specialists only, but may synergize greatly if resources from other grouping are also included. Consider how having the following units can greatly impact how your team can perform in certain situations:
- Cyber Security Specialist - We all know these belong on the team.
- Security Operations - They might have insights into developing matters and can support with a birds eye view of the situation.
- IT-Operations
- Network Operations
- Development
- Legal
- HR
PICERL - A Methodology
The PICERL Methodology is formally called NIST-SP 800-61 (https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf) and contains an overview of a methodology which can be applied to incident response.
Do not consider this methodology as a waterfall model, but instead as a process where you can go forwards and backwards. This is important to ensure you fully deal with incidents that happen.
The 6 stages of Incident Response:
Preparation
This phase is for getting ready to deal with incident response. There are many things an IRT should consider to make sure they are prepared.
Preparation should include development of playbooks and procedures which dictates how the organization should respond to certain kinds of incidents. Rules of Engagement should also be determined in advance: how should the team respond? Should the team actively try to contain and clear threats, or is it sometimes acceptable to monitor a threat in the environment to learn valuable intelligence on for example how they broke in, who they are and what they are after?
The team should also ensure they have the necessary logs, information and access needed to conduct responses. If the team cannot access the systems they are responding on, or if the systems can not accurately describe the incident, the team is set up for failure.
Tools and documentation should be up to date and safe communication channels already negotiated. The team should ensure the necessary business units and managers can receive continuous updates on the development of incidents which impact them.
Training for both the team and supporting parts of the organization is also essential for the teams success. Incident Responders can seek training and certifications and the team can try influence the rest of the organization to not become victims of threats.
Identification
Looking through data and events, trying to point our finger at something which should be classified as an incident. This task is often sourced to the SOC, but the IRT can partake in this activity and with their knowledge try improve the identification.
Incidents are often created based on alerts from security related tools such as EDR ("Endpoint Detection and Response"), IDS/IPS ("Intrusion Detection/Prevention Systems") or SIEM's ("Security Information Event Management System"). Incidents can also occur by someone telling the team of a problem, for example a user calling the team, an email to the IRT's email inbox or a ticket in a incident case management system.
The goal of the identification phase is to discover incidents and conclude their impact and reach. Important questions the team should ask themselves include:
- What is the criticality and sensitivity of the platform breached?
- Is the platform used elsewhere, meaning there is a potential for further compromise if nothing is done in time?
- How many users and systems are involved?
- What kinds of credentials has the attackers got, and where else can they be re-used?
If an incident needs to be responded to, the team moves into the next phase containment.
Containment
Containment should try stop the attackers in their tracks and prevent further damages. This step should ensure the organization does not incur any more damages and ensure the attackers can not reach their objectives.
The IRT should as soon as possible consider if a backup and imaging should be done. Backup and imaging is useful to preserve evidence for later. This process should try to secure:
- A copy of the hard-drives involved for file forensics
- A copy of the memory of the involved systems for memory forensics
There are many actions the IRT can do to stop the attackers, which very much depends on the incident in question:
- Blocking the attackers in the Firewall
- Disconnecting network connectivity to the compromised systems
- Turning systems offline
- Changing passwords
- Asking ISP ("Internet Service Provider") or other partners for help in stopping the attackers
Actions performed in the containment phase tries to quickly terminate the attacker so the IRT can move into the eradication phase.
Eradication
If containment has been properly performed, the IRT can move into the eradication phase, sometimes called the remediation phase. In this phase the goal is to remove the attackers artifacts.
There are quick options to ensure eradication, for example:
- Restoring from a known good backup
- Rebuilding the service
If changes and configurations have been implemented as part of containment, keep in mind that restoring or rebuilding may undo these changes and they would have to be reapplied. Sometimes, however, IRT must manually try to remove the artifacts left behind from an attacker.
Recovery
Restoring to normal operations is the target state for the IRT. This might involve acceptance testing from the business units. Ideally we add monitoring solutions with information about the incident. We want to discover if the attackers suddenly return, for example because of artifacts we failed to remove during eradication.
Lessons Learned
The final phase involves us taking lessons from the incident. There is bound to be many lessons from the incident, for example:
- Did the IRT have the necessary knowledge, tools and accesses to perform their work with high efficiency?
- Was there any logs missing which could have made the IRT efforts easier and faster?
- Are there any processes that could be improved to prevent similar incidents taking place in the future?
The lessons learned phase typically concludes a report that details an executive summary and overview over all which took place during the incident.
Cyber Security Quiz
You can test your Cyber Security skills with W3Schools' Quiz.
The Test
The test contains 25 questions and there is no time limit.
The test is not official, it's just a nice way to see how much you know, or don't know, about Cyber Security.
Count Your Score
You will get 1 point for each correct answer. At the end of the Quiz, your total score will be displayed. Maximum score is 25 points.
Start the Quiz
Good luck!
If you don't know Cyber Security, we suggest that you read our from scratch.
Kickstart your career
Get certified by completing the course
w3schools CERTIFIED . 2023
Cyber Security Exam
| w3schools CERTIFIED . 2023 |
|
W3Schools offers an Online Certification Program.
The perfect solution for busy professionals who need to balance work, family, and career building.
More than 50 000 certificates already issued!
|
w3schools CERTIFIED . 2023
W3Schools offers an Online Certification Program.
The perfect solution for busy professionals who need to balance work, family, and career building.
More than 50 000 certificates already issued!
Document your skills
Improve your career
Study at your own pace
Save time and money
Known brand
Trusted by top companies
Who Should Consider Getting Certified?
Any student or professional within the digital industry.
Certifications are valuable assets to gain trust and demonstrate knowledge to your clients, current or future employers on a ever increasing competitive market.
W3Schools is Trusted by Top Companies
W3Schools has over two decades of experience with teaching coding online.
Our certificates are recognized and valued by companies looking to employ skilled developers.
Save Time and Money
Show the world your coding skills by getting a certification.
The prices is a small fraction compared to the price of traditional education.
Document and validate your competence by getting certified!
Exam overview
Fee: 45 USD
Number of questions: 70
Requirement to pass: 75% correct answers
Time limit: 70 minutes
Number of attempts to pass: Two
Exam deadline: None
Certification Expiration: None
Format: Online, multiple choice
Advance Faster in Your Career
Getting a certificate proves your commitment to upgrading your skills.
The certificate can be added as credentials to your CV, Resume, LinkedIn profile, and so on.
It gives you the credibility needed for more responsibilities, larger projects, and a higher salary.
Knowledge is power, especially in the current job market.
Documentation of your skills enables you to advance your career or helps you to start a new one.
How Does It Work?
- Study for free at W3Schools.com
- Study at your own speed
- Test your skills with W3Schools online quizzes
- Apply for your certificate by paying an exam fee
- Take your exam online, at any time, and from any location
Get Your Certificate and Share It With The World
Example certificate:

Each certificate gets a unique link that can be shared with others.
Validate your certification with the link or QR code.
Check how it looks like in this .
Share your certificate on LinkedIn in the Certifications section in just one click!
Document Your Skills
Getting a certificate proves your commitment to upgrade your skills, gives you the credibility needed for more responsibilities, larger projects, and a higher salary.
Looking to add multiple users?
Are you an educator, manager or business owner looking for courses or certifications?
We are working with schools, companies and organizations from all over the world.
Login




.png)

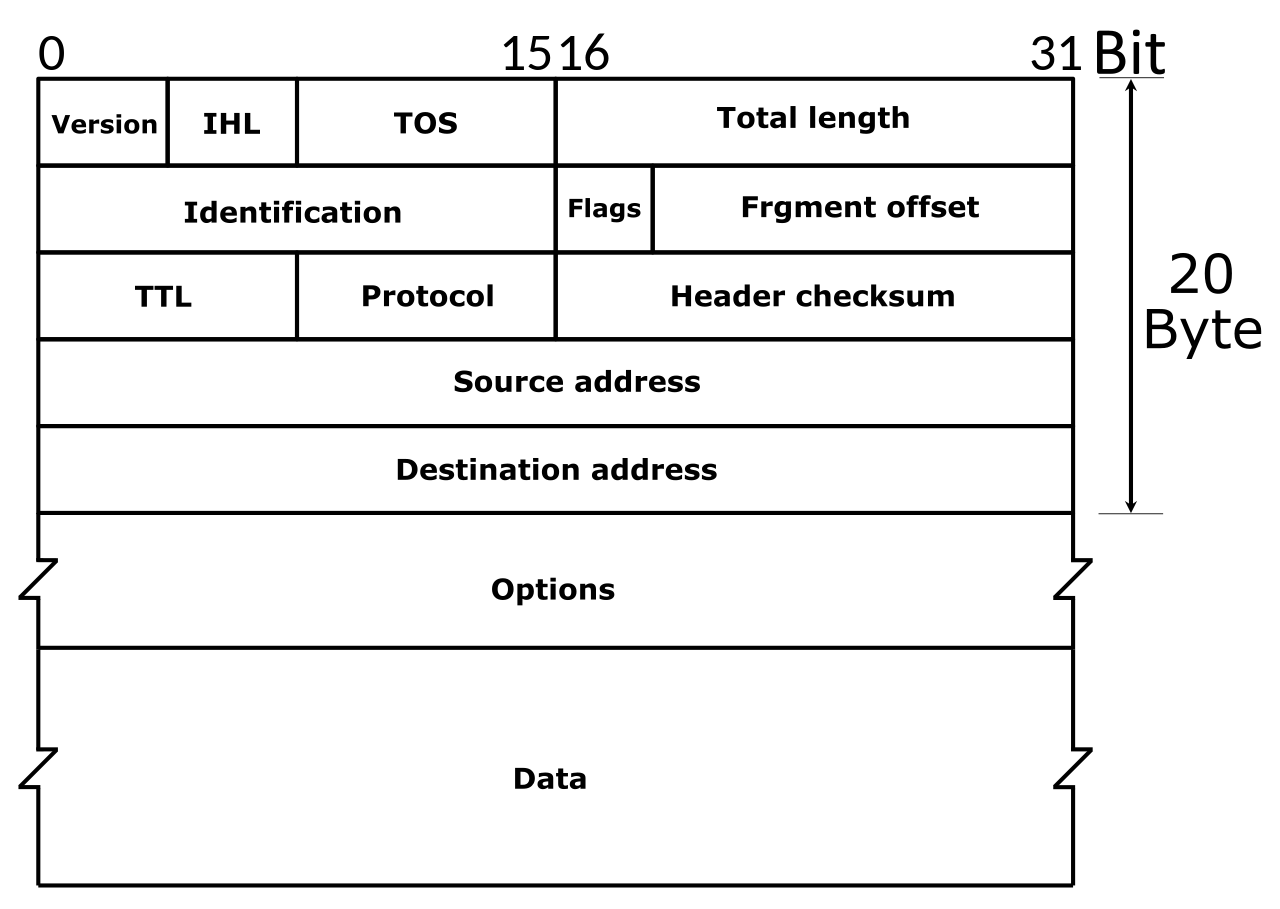


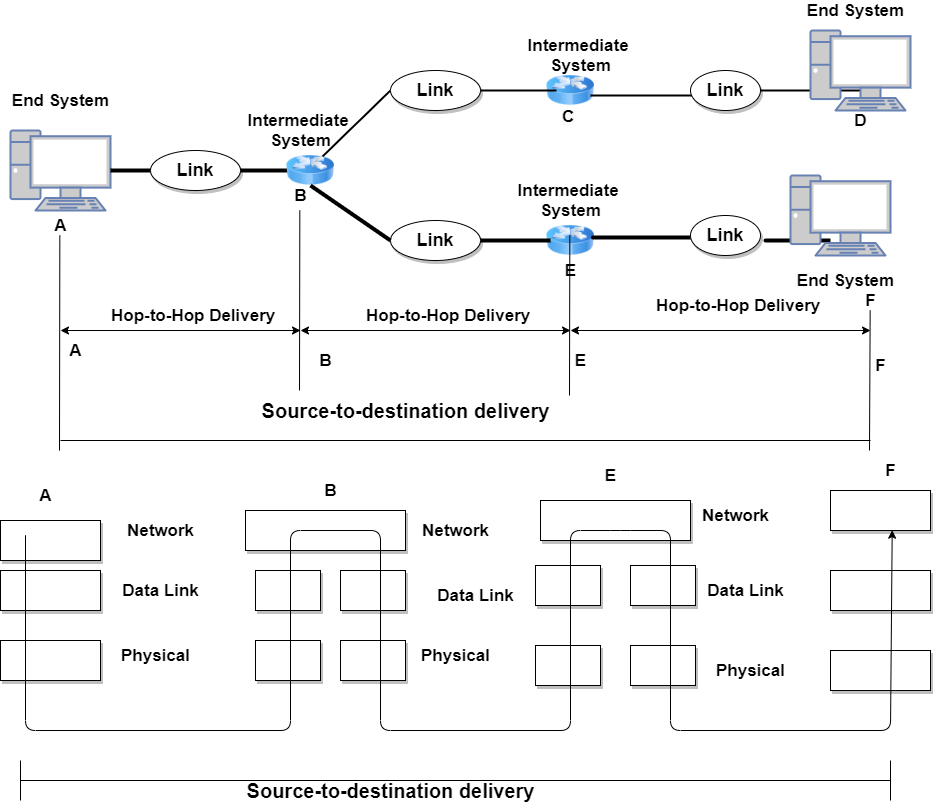

 owing attackers to send traffic on behalf of others.
owing attackers to send traffic on behalf of others.






.png)